
Если вы думали, что для создания качественного дипфейка вам нужен супер-компьютер или как минимум мощная видеокарта, то я вас обрадую. Сегодня я расскажу, как создать дипфейк, даже если у вас компьютер из начала 2000-ых.
Этот гайд даст вам исчерпывающую информацию, чтобы делать подобные дипфейки - посмотреть deepfake на YouTube. Это был мой первый дипфейк, сейчас получается намного лучше. Я постарался максимально подробно и просто рассказать все что знаю, поэтому материал получился довольно большой.


Раньше, чтобы добиться подобного качества, нужно было быть фотошопером от бога. Сначала разбить видео на кадры, на каждом кадре заменить лицо, слепить полученные кадры снова в видео, вот и дипфейк готов. Никто этим не занимался, так как это слишком сложно. Теперь у нас есть нейронные сети, которые позволяют все это сделать за нас.
Вроде все хорошо, но есть загвоздки:
- Для работы с нейронными сетями нужна мощная видеокарта. А лучше сразу несколько.
- Нужен большой набор фотографий, для обучения нейронки.
Помимо майнинга, видеокарты отлично справляются с созданием дипфейков. Но что делать, если у вас вместо нормальной видеокарты Intel HD Graphics. Не покупать же новую в эпоху майнинга 😄
Google Colab
К счастью, одну проблему легко решить. Google предоставляет бесплатный облачный сервис Google Colaboratory, который позволяет вам запускать код на Python из браузера, используя при этом мощный графический процессор.
У вас в распоряжении оказывается доступ к серверу с 70 Gb памяти, и что самое важное - с одной из мощных видеокарт от Nvidea: K80, T4, P4 или P100. И все это совершенно бесплатно, но с некоторыми ограничениями:
-
Colab запускается из браузера, и если вы закроете вкладку, то работа программы остановится. На создание одного дипфейка уходит от 2 дней. Все это время компьютер должен работать.
-
При этом время непрерывной сессии 12 часов. Когда вы подключаетесь к Colab, специальный алгоритм решает давать вам ресурсы GPU или нет. Если вам выделяют ресурсы, то они доступны вам 12 часов. Далее вы снова встаете в очередь. Но на практике это время еще меньше.
Частично эту проблему решает создание нескольких аккаунтов. Но и это не всегда помогает, я создал пять аккаунтов и все равно мог не получить сервер.
-
Также временами будет всплывать капча, чтобы подтвердить, что вы на месте. Появление капчи не зависит от вашей активности в браузере, она просто будет появляться время от времени. Поэтому никакая имитация деятельности не поможет. Проверенно 😁
Не пугайтесь этой фразы "у вас в распоряжении оказывается сервер". На самом деле все намного проще, так как все управление происходит с помощью сайта. С этим справится даже школьник, поверьте.
Забегая вперед скажу, что существует Pro версия сервиса за 10$, которая лишина многих этих недостатков. Но и с бесплатной версией вполне можно работать.
DeepFaceLab (DFL)
Для создания дипфейка мы будем использовать проект DeepFaceLab [DFL 2.0], а точнее его слегка урезанную версию для Colab. У полноценной версии DFL есть визуальный редактор, который упрощает создание дипфейка.
Давайте для начала разберемся, как устроено создание дипфейка в общих чертах.
Общее описание работы
Для создания дипфейка нам нужна обученная модель нейронной сети. Именно нейронная сеть будет "превращать" одно лицо в другое. А чтобы она смогла это делать, ее нужно натренировать.
Тренировка довольно долгий процесс, обычно занимает несколько дней. Чем дольше тренируется модель, тем более правдоподобный получится результат.
Для тренировки понадобятся два набора лиц, проще говоря коллекция фотографий. В первом наборе (data_dst) будут целевые лица - это лица, на которых мы будем заменять лицо. В другом наборе (data_src) лица источника - это лица, которые будут использоваться для замены.
Самый простой способ получить эти наборы лиц - это использовать видеозаписи. Видео делится на кадры, из кадров выделяются картинки с лицами. Не пугайтесь, вам нужно только представить видео или фотографии, а программа сама вырежет из них квадраты с лицами.
Видео с целевым лицом называется data_dst.mp4, видео с лицом источника - data_src.mp4. Для наборов не обязательно использовать видео, можно использовать наборы фотографии.
Далее на наборах лиц происходит тренировка модели нейронной сети. Проще говоря, нейронная сеть сама учится что надо изменить, чтобы из первого человка сделать второго.
Тренировка не быстрый итеративный процесс. На первых итерациях у нейронной сети будет получаться какая-то каша, но с каждой новой итерацией нейронная сеть будет приближаться к необходимому результату.
После окончания обучения происходит слияние. Сначала на исходных кадрах видео лица заменяются по обученной модели. После наложения происходит склейка кадров обратно в видео с названием result.mp4, звуковая дорожка для этого видео берется из файла data_dst.mp4. Так и получается дипфейк.
Структура проекта
Разберемся со структорой проекта DFL, чтобы понимать что где лежит и за что отвечает. Все файлы лежат в папке workspace. В этой папке находятся другие папки и ресурсы, которые необходимы для обучения модели.
data_src- это папка, в которой хранятся кадры, извлеченные из файлаdata_src.mp4.
После извлечения лиц из кадров создается подпапка:aligned- изображения лиц, со встроенными данными лицевых ориентиров.
data_dst- это папка, в которой хранятся кадры, извлеченные из файла data_dst.mp4.
Как и в случае сdata_src, после извлечения лиц создается подпапкаalignedmerger- кадры видеоdata_dst, в которых уже заменено лицо.
model- папка хранит модель нейронной сети. Создается после начала обучения.result.mp4- этот файл создается после Merge. Является непосредственно дипфейком.
Я уже упоминал, что нам нужны видео, из которых мы будем извлекать лица:
- для
data_dstнеобходимо подготовить целевое видео и назвать егоdata_dst.mp4. Это видео помещается в папкуworkspace. - для
data_srcвы должны либо подготовить исходное видео и назвать егоdata_src.mp4, либо подготовить изображения в формате jpg/png.
Также в процессе обучения может закончиться память на гугл-диске, что приведет к проблемам.
Подготовка к созданию
Перед обучением, нам необходимо получить изображения, из которых DFL сформирует наборы лиц для обучения. Для примера, создадим дипфейк из фрагмента видео Marvel. В нем железный человек забирает у человека-паука костюм.
Создадим новый проект DFL. Для этого создаем на компьютере папку workspace. Все папки и файлы далее будем создавать в ней.
Получаем набор data_src
Непосредственно набор для нас сделает DFL. От нас требуется предоставить для него изображения, из которых DFL вырежет квадраты с лицами.
Вы можете либо самостоятельно добавить изображения в формате png/jpg в папку data_src, либо можете добавить видео data_src.mp4 в workspace, после чего с помощью DFL нарезать его на кадры, и уже потом вырезать квадраты с лицами для набора.
Советы для записи видео
- Снимайте лицо с разных ракурсов. А также желательно при разном освещении.
- Изображайте какие-нибудь эмоции: гнев, радость. Алгоритм будет искать похожие по эмоциям лица. В идеале спародировать фрагмент видео.
- Открывайте рот, а лучше что-то говорите в камеру. Если вы снимите видео, где рот не открывается, алгоритм не откроет его за вас. Улыбнитесь, покажите зубы и так далее.
- Моргайте, а лучше закройте на несколько секунд глаза. В противном случае ваш дипфейк не будет моргать.
Получаем набор data_dst
Здесь все проще, ведь у вас есть видео data_dst.mp4. Вы можете дополнительно добавить в папку data_dst изображения с заменяемым лицом из других источников, в таком случае модель будет обучаться лучше. Но обычно достаточно тех кадров, что есть в видео.
Загружаем workspace в Google Drive
Нам нужно загрузить нашу папку в Google Drive, чтобы Google Colab мог получить к ней доступ.
Папку workspace архивируем таким образом, чтобы в архиве содержалась непосредственно папка workspace. Если в архиве будет сразу два видео или другие папки, то вы сделали все неправильно.
Теперь загрузите этот архив на гугл диск.
Создание Deepfake
Переходим в Colab
Открываем проект Colab в браузере.
Установка DFL
Перед установкой DFL проверим, какую GPU мы получили. Найдите раздел “Check GPU”, нажмите на “скрыта одна ячейка”, и запустите !nvidia-smi.
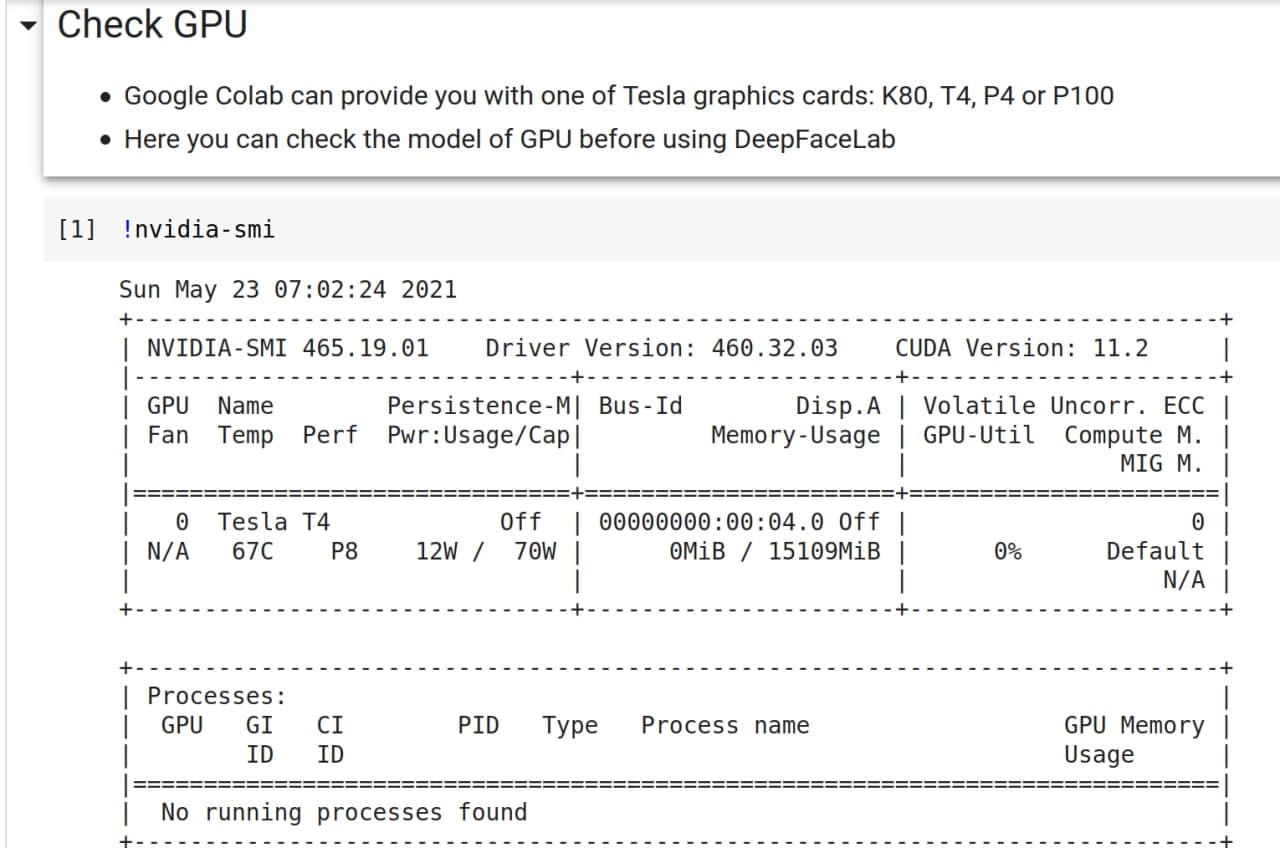
Эта GPU обеспечивают скорость тренировки 0.6-0.7 секунд за итерацию обучения модели. Остальные дают 1.3-1.4 секунд за итерацию. В идеале нужно выполнить 300000+ итераций обучения модели, так что выгоду считайте сами.
Переходим к пункту “Install or update DeepFaceLab”. И жмем на кнопку “Скрыта одна ячейка”, после жмем на треугольник запуска.
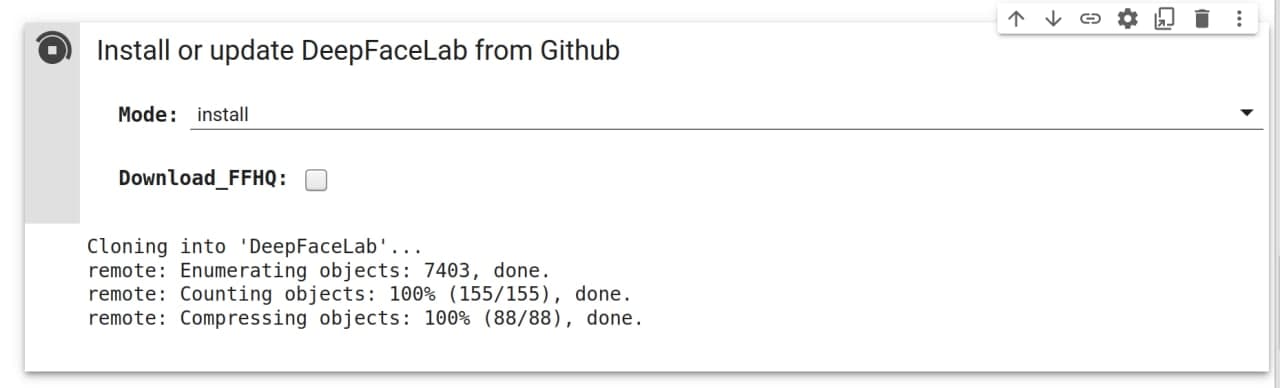
В процессе установки могут возникать ошибки подобного вида:

Не обращайте на них внимания, они не повлияют на работу.
Загрузка проекта
Через минут 5, после установки, переходим к “Manage workspace”. Нажимаем на плашку “скрыто 5 ячеек”.
Colab работает как докер, как только вы закрываете проект или браузер, все данные стираются. Поэтому держите браузер открытым, во время работы. Но даже несмотря на это могут происходить сбои, а процесс обучения довольно длинный, поэтому предусмотрено создание бэкапов на гугл диск каждый час.
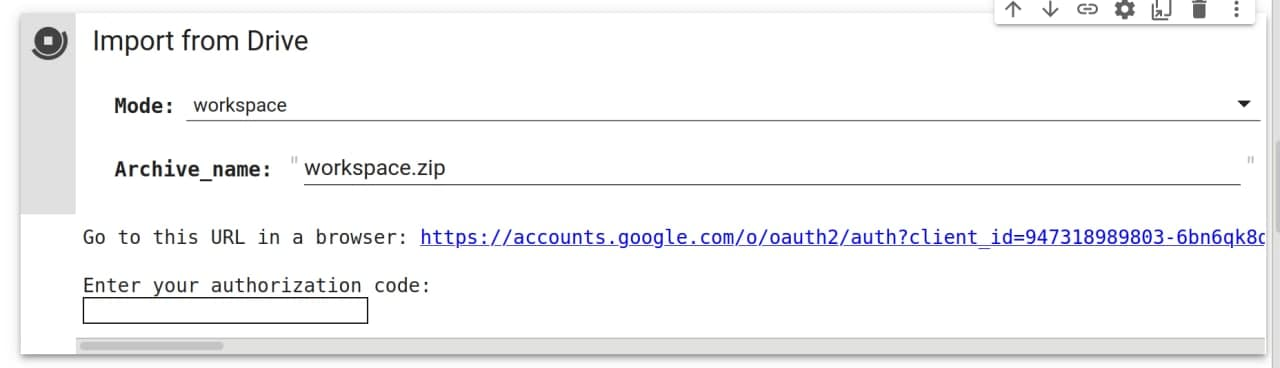
Переходим к загрузке проекта в Colab. Пункт “Import from Drive” позволяет загрузить и распаковать проект с вашего гугл диска. Этот пункт также позволяет загружать отдельные части проекта, например только лица или только папку data_src.
Нам нужно загрузить workspace.zip с гугл диска. После запуска вам необходимо перейти по ссылке из консоли и разрешить доступ к диску.

Если все прошло успешно, то вы должны увидеть папку вашего проекта. Для этого есть кнопка слева под логотипом Colab.
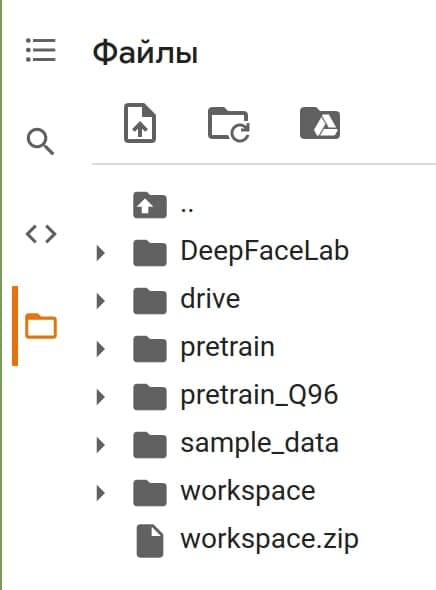
Об остальных пунктах в разделе:
- Пункт ниже “Export to Drive” позволяет скачать проект на гугл диск. Тут тоже можно выбрать не только весь проект, но и отдельные папки. Например, скачать только натренированную нейросетью модель.
- Пункты “Import from URL” и “Export to URL” позволяют загружать и скачивать проект удаленно.
- Пункт “Delete and recreate” позволяет очистить проект или часть про
Выделяем лица
Разворачиваем пункт “Extract, sorting and faceset tools”.
“Extract frames” разобьет наше видео на кадры, из которых мы вырежем лица для обучения нашей модели. Выбираем нужное видео, нажимаем пуск. В итоге получаем кадры видео либо в папке data_src, либо в папке data_dst. Если вы используете картинки вместо видео, то пропустите этот пункт для data_src.
“Denoise frames” отвечает за понижение шумов на кадрах видео. Запускайте его по желанию.
Теперь из кадров необходимо вырезать лица. За это отвечает пункт “Detect faces”. Запускаем для каждого видео. И получаем папки aligned в папках data_dst и data_src.
/content
[wf] Face type ( f/wf/head ?:help ) : wf
[0] Max number of faces from image ( ?:help ) : 0
[512] Image size ( 256-2048 ?:help ) : 720
[90] Jpeg quality ( 1-100 ?:help ) : 90
Extracting faces...Очищаем набор лиц
Далее очищаем набор лиц от ложных срабатываний и/или неправильно выровненных лиц.
Скачиваем папки aligned c помощью пункта “Export to Drive” в “Manage workspace”. Этот пункт загрузит папки в виде архива в гугл диск, скачайте их оттуда и распакуйте. После чего проверьте, какие лица попали в выборку, удалите плохие.
Плохие лица для data_src/aligned:
- Закрытые предметами лица.
- Перевернутые лица
- Сильно обрезанные лица
- Размытые лица
Плохие лица для data_dst/aligned:
- Сильно обрезанные лица
- Лица, которые вы не собираетесь заменять
Плохие лица для data_dst и data_src отличаются, к data_src предъявляется более строгие требования, тогда как перестаравшись в удалении data_dst вы получите кадры без наложения лица.
Вот пример data_src/aligned перед очисткой с цветовой кодировкой лиц в соответствии с тем, что вы должны с ними делать.

- Зеленый - хорошее выравнивание лиц.
- Красный - смещенные. Они немного повернуты. Их стоит удалить.
- Синий - препятствие поверх лица. Можно оставить, если это всего лишь небольшое препятствие на нескольких гранях во всем наборе.
- Желтый - размытые лица. Следует удалить, если только это не уникальное положение головы, которых больше в наборе нет. Небольшое количество может помочь обобщить лицо. Не стоит оставлять больше 5% от набора данных.
- Фиолетовый - лица других людей. Очевидно, что их нужно удалить.
- Розовый - обрезанные лица. Их можно оставить, если обрезано только немного подбородка или лба, при условии, что это всего несколько лиц во всем наборе данных, или если присутствует уникальное положение головы.
- Оранжевый - любые изображения с сильными фотоинстаграм-фильтрами и прочим. Если они лишь немного отличаются от остальных, можно оставить, предполагая, что используется передача цвета во время обучения, чтобы усреднить их всех по сравнению с другими и DST.
После очистки заархивируйте папки и загрузите на гугл-диск. После чего загрузите обратно в проект очищенные лица.
“Faceset Enhancer”
Пункт “Faceset Enhancer” позволит улучшить детализацию ваших наборов лиц. Используйте по желанию.
Я использую этот пункт только для data_srcXSeg mask
Если в вашем видео заменяемое лицо перекрывается каким-то предметами, например лицо трогают руками, то вам необходимо для data_dst выполнить пункт “Apply or remove XSeg mask to the faces”. Если на видео лицо не перекрывается, то делать этого не надо.
Запускаем тренировку
Теперь мы можем приступить к тренировке нейронной сети. Переходим к пункту “Training”.
Нейронная сеть будет итеративно обучать модель. Как я уже говорил необходимо около 200-300к итераций, чтобы добиться хорошего качества дипфейка. Скорость выполнения одной итерации варьируется от параметров тренировки и вашей GPU и может принимать значения от 0.3 секунд до 1.2 секунд.
Пройдемся по параметрам тренировки. Некоторые параметры можно изменять в процессе обучения, чтобы улучшить обучаемость модели. А некоторые категорически нельзя изменять. Об этих нюансах я расскажу далее.
Параметр Silent_Start отвечает за повторный запуск с последними параметрами тренировки. Отключаем этот пункт, так как у нас не было тренировок. Также этот пункт надо отключать, если вы хотите изменить какой-либо параметр в процессе тренировки. Тогда после выбора модели и GPU надо нажать Enter в течение двух секунд.
/content
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
Creating workspace archive ...
Archive created!
Time to end session: 12 hours
Running trainer.
[new] No saved models found. Enter a name of a new model : tony_stark
Model first run.
Silent start: choosed device Tesla T4Нам сообщают, что бэкап создан, и у нас еще 12 часов серверного времени. И просят ввести название модели.
[0] Autobackup every N hour ( 0..24 ?:help ) : 0Как часто делать бекапы, оставляем значение 0. Мы уже указали галкой, что бекапы делать каждый час.
[n] Choose image for the preview history ( y/n ) : nСохранять изображения предварительного просмотра во время тренировки каждые несколько минут. Если вы выберете «Да», вы получите еще один запрос.
[n] Write preview history ( y/n ?:help ) : nВыберите изображение для истории предварительного просмотра: если вы выберете N, модель будет выбирать грани для предварительного просмотра случайным образом, при выборе Y должно открыться новое окно после, где вы сможете выбрать их вручную.
Так как мы работаем в Colab, то никакого окна не получим, лучше выбрать n.
[0] Target iteration : 0Количество повторений, после которого обучение прекратится. Если поставить 0, то обучение будет бесконечным.
Чем больше итераций, тем лучше получится дипфейк. Оптимально 300к-500к итераций.
При дефолтных параметрах ниже на Colab Pro вы получаете скорость в 0.3-0.4 секунды за итерацию. Это позволяет за ночь выполнить более 100000 итераций. В бесплатном Colab вы получаете 0.6-0.7 секунды за итерацию, это позволяет за ночь выполнить чуть более 50000 итераций, но скорее всего будет меньше из-за капчи, которая прервет обучение.
[n] Flip SRC faces randomly ( y/n ?:help ) : nСлучайно переворачивает грани src по горизонтали. Помогает покрыть все углы, присутствующие в наборе данных dst, гранями src в результате их переворачивания, что иногда может быть полезно. Особенно если в нашем наборе немного разных условий освещения, но во многих случаях результаты будут казаться неестественными, поскольку лица никогда не бывают идеально симметричными.
Рекомендуется использовать только на ранних этапах обучения или не использовать вообще, если наш набор data_src достаточно разнообразен.
[y] Flip DST faces randomly ( y/n ?:help ) : yСлучайное переворачивание граней dst по горизонтали, может улучшить обобщение, если предыдущий параметр отключен.
[8] Batch_size ( ?:help ) : 8Параметры размера пакета влияют на количество лиц, сравниваемых друг с другом на каждой итерации. Наименьшее значение - 2.
Чем выше разрешение, размеры и больше функций у ваших моделей, тем больше потребуется VRAM, поэтому может потребоваться меньший размер пакета. Не рекомендуется использовать значение ниже 4. Чем больше размер пакета, тем выше качество за счет более медленного обучения, более продолжительного времени итерации.
Для начальной стадии можно установить более низкое значение, чтобы ускорить начальное обучение, а затем повысить его. Оптимальные значения - от 6 до 12.
[128] Resolution ( 64-640 ?:help ) : 128Разрешение ваших моделей. Это влияет на разрешение замененных лиц, чем выше разрешение модели - тем детальнее будет изученное лицо, но и обучение будет намного тяжелее и дольше.
Разрешение может быть увеличено с 64x64 до 640x640 с шагом:
- 16 (для вариантов с обычной архитектурой и -U)
- 32 (для вариантов с архитектурой -D и -UD)
Изменение этого параметра ведет к изменениям других параметров, вследствие чего скорость итерации может замедлиться более чем в 2 раза.
Если вы используете Colab Pro, то можете увеличить Resolution до 192.
[f] Face type ( h/mf/f/wf/head ?:help ) : wfЭта опция позволяет вам установить область лица, которую вы хотите тренировать, есть 5 вариантов - половина лица, середина половины лица, анфас, все лицо и голова:
Half face (HF)
Тренируется только область ото рта до бровей, но в некоторых случаях может отрезать верхнюю или нижнюю часть лица: брови, подбородок, кусочек рта.
Mid-half face (MHF)
Направлена на решение проблемы HF, покрывая на 30% большую часть лица по сравнению с половиной лица, что должно предотвратить возникновение большинства нежелательных обрезаний, но они все же могут произойти.
Full face (FF)
Покрывает большую часть области лица, за исключением лба, иногда может отрезать немного подбородка, но это случается очень редко - только когда объект широко открывает рот). Наиболее рекомендуется, когда SRC и или DST имеют волосы, покрывающие лоб.
Whole face (WF)
Расширяет эту область еще больше, чтобы покрыть практически все лицо, включая лоб и все лицо сбоку, вплоть до ушей.
Head (HEAD)
Используется для замены всей головы, не подходит для людей с длинными волосами. Лучше всего работает, если исходный набор данных faceset поступает из одного источника, и как SRC, так и DST имеют короткие волосы или волосы, форма которых не меняется в зависимости от угла.
Лучший вариант это WF.
[liae-ud] AE architecture ( ?:help ) : liae-udAE architecture (df/liae/df-u/liae-u/df-d/liae-d/df-ud/liae-ud ?:help ) : Этот вариант позволяет вам выбирать между двумя основными архитектурами обучения:DF и LIAE, а также их варианты -U, -D и -UD.
DF
Эта архитектура модели обеспечивает более прямую замену лиц, не трансформирует лица, но требует, чтобы лицо исходного и целевого назначения имело схожую форму, в то время как черты лица (формы рта, глаз, носа) могут отличаться больше, чем при LIAE. Лучше работает с фронтальными снимками и требует, чтобы исходный набор данных имел все необходимые углы, может давать худшие результаты на боковых профилях, чем LIAE.
LIAE
Эта архитектура модели не столь строгая, когда речь идет о сходстве формы лица между источником и целевым местом назначения, но черты лица (формы глаз, носа, рта) должны быть схожими для хороших результатов. Эта модель предлагает худшее сходство с источником, чем DF, но может лучше обрабатывать боковые профили и более снисходительна, когда дело доходит до набора данных исходного лица, в котором отсутствуют некоторые углы, выражения или условия освещения, часто дает более точные смены лиц с лучшим соответствием цветового освещения.
DF-U/LIAE-U
Этот вариант направлен на улучшение сходства с исходными лицами.
DF-D/LIAE-D
Этот вариант направлен на повышение производительности за счет примерно удвоения возможного разрешения без дополнительных затрат на вычисления (использование VRAM) и аналогичной производительности. Однако для этого требуется более длительное обучение, модель должна быть предварительно обучена для получения оптимальных результатов, а разрешение должно быть изменено на значение 32, в отличие от 16 в других вариантах.
DF-UD/LIAE-UD
Объединяет оба варианта для максимального сходства и повышения разрешения. Также требуется более длительное обучение и предварительная подготовка модели.
Следующие 4 параметра управляют размерами нейронных сетей моделей, которые влияют на способность моделей к обучению, их изменение может иметь большое влияние на производительность и качество.
Если вы повысили пункт Resolution, то необходимо увеличить и эти пункты, иначе улучшения качества не добиться.
Для Resolution: 192
AutoEncoder dimensions: 384
Encoder dimensions: 96
Decoder dimensions: 96
Decoder mask dimensions: 33
Мои параметры для Colab Pro замедляют обучение в 2 раза. Таким образом мы получаем скорость обучения, как в бесплатной версии Colab, но с повышенным качеством.
[256] AutoEncoder dimensions ( 32-1024 ?:help ) : 256Настройка AutoEncoder влияет на общую способность модели распознавать лица.
[64] Encoder dimensions ( 16-256 ?:help ) : 64Настройка Encoder влияет на способность модели узнавать общую структуру лиц.
[64] Decoder dimensions ( 16-256 ?:help ) : 64Настройка Decoder, влияет на способность модели распознавать мелкие детали.
[22] Decoder mask dimensions ( 16-256 ?:help ) : 22Decoder mask влияет на качество изученных масок.
Изменения каждого параметра могут по-разному влиять на производительность, и невозможно измерить влияние каждого из них на производительность и качество без тщательного тестирования.
Для каждого параметра установлено значение по умолчанию, которое должно обеспечивать оптимальные результаты и хороший компромисс между скоростью и качеством обучения.
Кроме того, при изменении одного параметра следует изменить и другие, чтобы отношения между ними оставались одинаковыми.
[y] Masked training ( y/n ?:help ) : yОтдает приоритет обучению того, что замаскировано (маска по умолчанию или примененная маска xseg), доступно только для типов лиц WF и HEAD, при отключении тренирует всю область образца (включая фон) с тем же приоритетом, что и само лицо.
[n] Eyes and mouth priority ( y/n ?:help ) : nПопытки исправить проблемы с глазами и ртом, включая зубы, обучив их более высокому приоритету, также могут улучшить их уровень резкости.
[n] Uniform yaw distribution of samples ( y/n ?:help ) : nПомогает при обучении граней профиля, заставляет модель тренироваться равномерно на всех гранях и устанавливает приоритеты для граней профиля. Может замедлять обучение фронтальных граней, включено по умолчанию во время предварительного обучения. Может использоваться, пока включен “random warp”, для улучшения обобщения сторон профиля лица или когда “random warp” отключен, чтобы улучшить качество и резкость деталей этих лиц.
Полезно, когда в исходном наборе данных не так много снимков профиля. Может помочь снизить размер потерь.
[y] Place models and optimizer on GPU ( y/n ?:help ) : yВключение оптимизатора графического процессора нагружает ваш графический процессор, что значительно повышает производительность (время итерации), но приводит к более высокому использованию видеопамяти, отключение этой функции переносит часть работы оптимизатора на центральный процессор, что снижает нагрузку на графический процессор и использование видеопамяти, что позволяет достичь большего размера пакета или запустить более требовательные модели за счет увеличения времени итерации.
[y] Use AdaBelief optimizer? ( y/n ?:help ) : yAdaBelief (AB) - это оптимизация модели, которая увеличивает точность модели и качество обученных лиц.
Когда эта опция включена, она заменяет оптимизатор RMSProp по умолчанию. Однако эти улучшения происходят за счет более высокого использования VRAM, что требует обучения существующих или новых моделей с меньшим размером пакета.
Эту опцию следует использовать только на новых моделях и всегда с самого начала, никогда не отключайте ее во время обучения, после включения она должна оставаться таковой.
[n] Use learning rate dropout ( n/y/cpu ?:help ) : n“learning rate dropout” используется для ускорения обучения лиц и уменьшения дрожания субпикселей - уменьшает дрожание лица и в некоторой степени также может уменьшить мерцание освещения.
В основном используется в 3 случаях:
- перед отключением “random warp”, когда значения потерь больше не улучшаются, это может помочь модели немного обобщить лица
- после того, как “random warp” был отключен и вы достаточно хорошо обучили модель, включение ее ближе к концу обучения приведет к более детальным, стабильным лицам, которые менее склонны к мерцанию
- после того, как вы немного потренировались с LARD, и лица выглядят так же хорошо, как вы можете включить GAN, и “learning rate dropout” следует оставить включенным во время его работы.
Если в вашей модели включен Adabelief, “learning rate dropout” не является обязательным, но все же рекомендуется, особенно при обучении GAN.
[y] Enable random warp of samples ( y/n ?:help ) : nСлучайная деформация используется для обобщения модели, чтобы она правильно учила черты лица и выражения на начальном этапе обучения. Но пока она включена, у модели могут возникнуть проблемы с изучением мелких деталей. Из-за этого рекомендуется держать эту функцию включенной до тех пор, пока ваши лица все еще улучшаются, и когда все выглядит правильно, вы должны отключить его, чтобы начать изучение деталей. Улучшение проверяйте глядя на уменьшение значений потерь и улучшение лиц в окне предварительного просмотра.
[0.0] GAN power ( 0.0 .. 1.0 ?:help ) : 0.0GAN расшифровывается как Generative Adversarial Network, а в случае DFL 2.0 он реализован как дополнительный способ обучения, чтобы получить более подробные и четкие лица. Этот параметр настраивается по шкале от 0,0 до 10,0, и его следует включать только после того, как модель более или менее полностью обучена (после того, как вы отключили случайную деформацию образцов и включили “learning rate dropout”).
Рекомендуется использовать низкие значения, например 0,01. Обязательно сделайте резервную копию своей модели перед началом обучения. После включения будут представлены еще две настройки для настройки внутренних параметров GAN:
[0.0] Face style power ( 0.0..100.0 ?:help ) : 0.0[0.0] Background style power ( 0.0..100.0 ?:help ) : 0.0Эти параметры управляют переносом стиля лица. Они используются для переноса стиля лиц data_dst на окончательное изученное лицо, что может улучшить качество и внешний вид после объединения. Но с высокими значениями может сделать лицо больше похожим на data_dst, чем на data_src.
Эта функция передаст некоторую информацию о цветовом освещении из DST в результирующее лицо, что может помочь с согласованием цветов и уменьшить мерцание, если передачи цвета недостаточно.
Рекомендуется не использовать значения выше 10. Начните с небольших значений, например 0,001–0,01, и увеличивайте их или начните с более высоких значений, например 1-2, и постепенно уменьшайте их.
Эта функция влияет на производительность, и ее использование увеличит время итерации и может потребовать от вас уменьшить размер пакета, отключить оптимизатор графических процессоров или запустить “learning rate dropout” на ЦП в результате более высокого использования VRAM.
[none] Color transfer for src faceset ( none/rct/lct/mkl/idt/sot ?:help ) : noneЭта функция используется для сопоставления цветов вашего data_src с data_dst, чтобы конечный результат имел цвет кожи, аналогичный data_dst, а конечный результат после обучения не менял цвета при перемещении лица, что может произойти, если были разные углы лица. На выбор есть несколько вариантов:
- none: в некоторых случаях вы можете получить лучшие результаты без передачи цвета во время тренировки.
- rct (reinhard color transfer): на основе: https://www.cs.tau.ac.il/~turkel/imagepapers/ColorTransfer.pdf
- lct (linear color transfer): Соответствует распределению цвета целевого изображения и исходного изображения с помощью линейного преобразования.
- mkl (Monge-Kantorovitch linear): на основе: http://www.mee.tcd.ie/~sigmedia/pmwiki/u…tie07b.pdf
- idt (Iterative Distribution Transfer): на основе: http://citeseerx.ist.psu.edu/viewdoc/dow…1&type=pdf
- sot (sliced optimal transfer): based on: https://dcoeurjo.github.io/OTColorTransfer/
Мы не будем использовать эту функцию на данном этапе, так как она замедляет обучение. Сопоставление цветов можно будет использовать уже на обученной модели, во время Merge.
[n] Enable gradient clipping ( y/n ?:help ) : yЭта функция реализована для предотвращения так называемого разрушения модели, которое может произойти при использовании различных функций DFL 2.0. Он имеет небольшое влияние на производительность, поэтому, если вы действительно не хотите его использовать, вы должны включить автоматическое резервное копирование, поскольку свернутая модель не может восстанавливаться и должна быть очищена, а обучение нужно начинать заново.
Значение по умолчанию - n (отключено), но поскольку влияние на производительность настолько низкое, это может сэкономить вам много времени, предотвращая разрушение модели, если вы включите эту функцию.
Разрушение модели, скорее всего, произойдет при использовании “Face style power”, поэтому, если вы их используете, настоятельно рекомендуется включить “gradient clipping” или резервное копирование.
[n] Enable pretraining mode ( y/n ?:help ) : nВключает процесс предварительного обучения, который использует набор данных из случайных лиц людей для первоначального обучения вашей модели. После обучения ее примерно до 200-400 тысяч итераций такую модель можно затем использовать при запуске обучения с фактическими данными data_src и data_dst, которые вы хотите обучить.
Это экономит время, потому что вы не нужно начинать обучение с нуля каждый раз. Модель будет «знать», как должны выглядеть лица, и, таким образом, ускорит начальный этап обучения.
Когда обучение начнется, вы увидите такую строку
[22:59:08][#003094][0662ms][0.4956][0.7795]- #003094 - это текущий номер итерации
- 0662ms - количество миллисекунд на одну итерацию
Во время обучения вы можете посмотреть насколько модель получается успешной. Для этого надо зайти в папку









Слияние
Первым делом необходимо наложить лицо data_src/aligned на кадры видео data_dst.
В процессе слияния вы можете заходить в папку data_dst/merged, чтобы посмотреть, как накладывается маска. Если результат вас не устраивает, то остановите Merge и запустите его с новыми параметрами.
В секции файлы существует ограничение, на показ количества файлов - отображается только первые 1000. Если вам нужно посмотреть 2000 кадр, то можно зайти в консоль сервера. Кнопка в левом нижнем углу.

Используем вот эту команду, чтобы скопировать нужный кадр в папку workspace:
cp workspace/data_dst/merged/00107.png workspace/Переходим в раздел “Merge frames” в пункт “Merge”. Тут тоже нужно будет выбрать параметры:
/content
Running merger.
Choose one of saved models, or enter a name to create a new model.
[r] : rename
[d] : delete
[0] : tony stark - latest : 0Предлагают выбрать модель, просто нажимаем Enter.
Loading tony stark_SAEHD model...
Choose one or several GPU idxs (separated by comma).
[CPU] : CPU
[0] : Tesla P100-PCIE-16GB
[0] Which GPU indexes to choose? : 0Выбираем на каком железе будем делать слияние, конечно на GPU.
Choose mode:
(0) original
(1) overlay
(2) hist-match
(3) seamless
(4) seamless-hist-match
(5) raw-rgb
(6) raw-predict
[1] : 3Выбираем способ слияния:
- original: отображает исходную рамку без замененного лица
- overlay: простое наложение выученного лица поверх рамки
- hist-match: накладывает выученное лицо на основе гистограммы.
- seamless: использует функцию opencv poisson seamless clone, чтобы смешать новое заученное лицо с исходным.
- seamless hist match: сочетает в себе hist-match и seamless
- raw-rgb: накладывает необработанное выученное лицо без какой-либо маскировки
Мне всегда подходит seamless или seamless-hist-match, остальные часто дают много артефактов.
Choose mask mode:
(1) dst
(2) learned-prd
(3) learned-dst
(4) learned-prd*learned-dst
(5) learned-prd+learned-dst
(6) XSeg-prd
(7) XSeg-dst
(8) XSeg-prd*XSeg-dst
(9) learned-prd*learned-dst*XSeg-prd*XSeg-dst
[1] : 4Выбираем режим маски.
- dst: использует маски, полученные из формы ориентиров, созданных во время data_dst.
- learned-prd: использует маски, полученные во время обучения. Сохраняет форму граней SRC.
- learned-dst: использует маски, полученные во время обучения. Сохраняйте форму граней DST.
- learned-prd*dst: совмещает обе маски, используя меньший размер обеих.
- learned-prd+dst: сочетает в себе обе маски, используя больший размер обеих.
- XSeg-prd: использует модель XSeg для маскировки с использованием данных из исходных лиц.
- XSeg-dst: использует модель XSeg для маскировки с использованием данных из конечных лиц.
- XSeg-prd*dst: совмещает обе маски, используя меньший размер обеих.
- learned-prddstXSeg-dst*prd: объединяет все 4 режима маски, используя меньший размер всех.
Для обученных моделей на XSeg лучше всего показывает себя learned-prd*dst. Если вы не использовали xseg, то вам также может хорошо подойти learned-prd.
[0] Choose erode mask modifier ( -400..400 ) : 0Эта функция управляет размером маски. Можно либо увеличить, либо уменьшить маску.
[0] Choose blur mask modifier ( 0..400 ) : 100Этот параметр отвечает за размытие края маски для более плавного перехода. Обычно можно четко видеть, где накладывается маска, при использовании этого параметра переход становится менее заметным, а может и пропасть вовсе.
Обычно я устанавливаю значение от 50 до 100.
[0] Choose motion blur power ( 0..100 ) : 0После ввода начальных параметров слияние загружает все кадры и данные, выровненные по data_dst, при этом вычисляет векторы движения, которые используются для создания эффекта размытия движения. Этот параметр позволяет вам добавить эффект размытия движения в местах, где лицо движется, но высокие значения могут размыть лицо даже при небольшом движении.
Опция работает, только если один набор лиц присутствует в папке data_dst/aligned. Если во время очистки у вас было несколько лиц с префиксом _1, даже если все лица одного человека, эффект не будет работать.
[0] Choose output face scale modifier ( -50..50 ) : 0Color transfer to predicted face ( rct/lct/mkl/mkl-m/idt/idt-m/sot-m/mix-m ) : idtЭтот пункт позволяет выровнять цвета на обученном лице. Я рассказывал уже об этих режимах выше в параметрах для тренировки, тогда мы не стали их применять для ускорения обучения, а сейчас самое время.
Чаще всего идеальным вариантом становится idt или idt-m. Если вы используете hist-match или seamless hist match, то не применяйте этот параметр.
Choose sharpen mode:
(0) None
(1) box
(2) gaussian
[0] ( ?:help ) : 0[0] Choose super resolution power ( 0..100 ?:help ) : 0
[0] Choose image degrade by denoise power ( 0..500 ) : 0
[0] Choose image degrade by bicubic rescale power ( 0..100 ) : 0
[0] Degrade color power of final image ( 0..100 ) : 0
[8] Number of workers? ( 1-4 ?:help ) : 8- degrade by denoise: Понижение шумов с помощью легкого размытия.
- degrade by bicubic rescale: размывает изображение бикубическим методом
После установки последнего параметра начинается слияние.
Сохранение видео
У нас есть кадры с наложенным лицом, но нет видео. Пункт “Get result video” в разделе “Merge frames” создаст видео result.mp4 и загрузит его в гугл-диск.
Заключение
Вот и все. Это было самое полное руководство по созданию дипфеков, которое я смог из себя выдавить 😄